
Why Can't AI Tell Jokes?
Hyperpolation is why AI is both so smart and so dumb

AI is amazingly impressive in a number of domains. But it has some weird defects. For example, it isn’t funny. I asked all the leading models to come up with ten original jokes. They were really bad:
My phone has “Night Mode,” but all it does is dim the screen and judge my life choices in lowercase.
I told my chemistry teacher I’d discovered a new element that only exists on Mondays. She said, “That’s not on the periodic table.” I said, “Of course not — it’s on the weakly table.”
I bought invisible ink to write my secrets, but now I can’t remember where I hid the pen.
Oof.
Despite AI being able to assist with science and knowing everything on the internet, it hasn’t come up with any novel scientific results on its own. That’s surprising. By default, I would expect that someone who learned everything in all of science would figure out lots of new insights. And yet the number of wholly AI-driven scientific discoveries is precisely zero.
It seems that AI has trouble with creativity. There’s some important sense in which it’s good at applying existing knowledge but not generating brand new ideas. Arguably, AI’s two biggest technical defects are inability to continually learn and limited creativity.
But why does AI struggle so much with creativity? The best solution to this puzzle that I’ve heard resides in a recent paper by Toby Ord with the salacious title Interpolation, Extrapolation, Hyperpolation: Generalising into new dimensions. This follows from a more general principle: on every topic, the best thing was written by Toby Ord.
You’ve probably heard of interpolation: estimating unknown values between known data points. Its twin extrapolation involves estimating values beyond a known range.
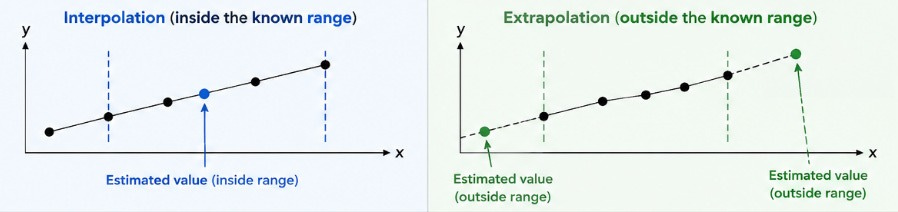
Ord coins a third term: hyperpolation. This is when you try to estimate unknown values by applying the existing pattern to a new dimension. In other words, while extrapolation applies some existing pattern to new points along the same dimension, hyperpolation applies it to a new dimension. You might hyperpolate to turn a 2-d function into a 3-d one.
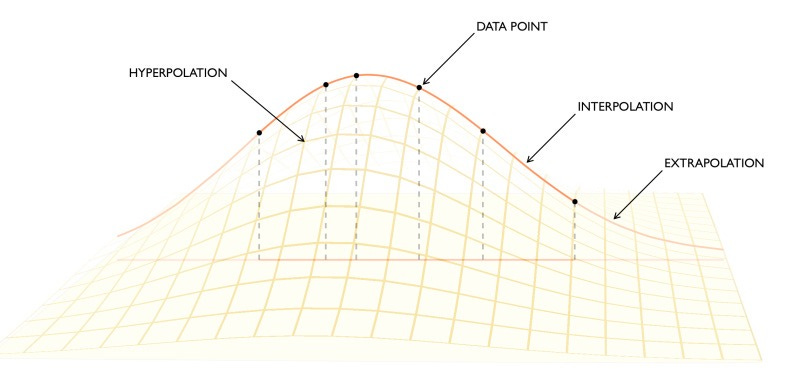
Now, you might be suspicious that there are better and worse ways of hyperpolating because for any function, there are infinite ways to hyperpolate it. But the same is true of interpolation and extrapolation—there are infinite functions that cut across any sequence of data points. As there are better and worse ways to interpolate and extrapolate, there are better and worse ways to hyperpolate. Ord’s paper discusses in detail the math behind how to hyperpolate properly.
What does this have to do with LLMs sucking at inventing new science and being failed comedians?
Behind an LLM is a sophisticated function. This includes a high-dimensional representation of concepts. By representing ideas in high-dimensional space, you can make increasingly accurate predictions of the next token. Connections between embeddings in high-dimensional space enable sophisticated concept acquisition. This is how generative AI models work, using a few tens of thousands of dimensions to encode ridiculously large amounts of information.
This is similar to how neurons work. Human concept acquisition comes from shared patterns of neuronal firings. Neurons that fire together wire together, allowing connections between neurons to embed sophisticated connections between concepts.
Ord’s thesis is that while AIs are amazingly good at extrapolation, they are bad at hyperpolation. Training shapes the function to fit the manifold of existing data extremely well. For this reason, LLMs are great at extrapolating their preexisting function to new points. But moving off that function to a new dimension is more difficult, and LLMs struggle with it.
This is a problem because hyperpolation is the essence of creativity. Being creative isn’t just about applying old ideas, but having brand new insights. If all you have is a very sophisticated embedding of the existing connections between old ideas, you’ll be good at applying old ideas but not at generating new ones.
To come up with a brand new joke or a novel scientific result, you don’t just need to apply old patterns between concepts in new ways. You need to expand the space of concepts entirely. As Ord put it:
Ideas like Mendelian inheritance, quantum mechanics, and non Euclidean geometry are not mere interpolations or extrapolations of existing ideas. They expanded the space of scientific ideas in fundamentally new directions. And much of the scientific work that we consider highly creative is also about finding new high-quality ideas that lie outside the existing subspace of ideas.
This is a useful framework for understanding the limits of AI. Why is AI bad at philosophy? A big part of philosophy is coming up with brand new arguments that no one has thought of before. Good philosophy involves hyperpolation. Applying existing ideas isn’t enough.
In contrast, AI is amazingly good at parodying authors. It has superhuman ability to parody people’s writing—I don’t know of anyone who could do an impression of David Bentley Hart complaining about French fries as well:
It is, I confess, with a kind of weary metaphysical exhaustion that I take up my pen to address that most pitiable of culinary atrocities — the so-called “French fry” — a phrase whose very Anglophone barbarism betrays its provenance among a people who long ago abandoned any serious commitment to the analogia entis in favor of a flatly materialist gastronomy.
But parody is about extrapolation. It’s about identifying patterns in what people say and applying them in new areas. You don’t need brand new insights to do good parodies. To do a good Trump impression, you don’t need to be Einstein.
At extrapolation and interpolation, AI is already wildly superhuman—at hyperpolation, it is mediocre. This is the source of its struggles in creative domains.
This doesn’t mean that AI models are just stochastic parrots. LLMs can generate new knowledge—they’re even able to come up with useful mathematical results that impress the world’s best mathematician. But they’re most successful at this when it involves applying existing tricks to new domains, rather than generating brand new insights. This isn’t, as critics claim, some deep fundamental insuperable challenge for all machine learning, meaning that AI will never be impressive (well, aside from already being a multi-trillion dollar industry). But it does mean that there’s a serious technical challenge for AI excellence across a number of domains.
LLMs have some ability to hyperpolate. But they’re bad at it, and this holds them back. In a deep sense, they struggle to move beyond the ideas present in their training data. The more some task involves applying old patterns to new domains, the better AIs are at it. The more it involves brand new insights, the worse they are.
So why can’t AI write jokes? My dad has a saying: “it’s all a question of vectors.” In this case, it really is!”
I'm curious to hear someone on the frontline of research give an estimate of the tractability here. This problem seems pretty robust against all the known methods of improving LLMs. It's gonna take some major hyperpolation on the part of the humans to finally pass that ability on to the silicon generation.
This reminds me of something I always get pulled back to thinking about which is the way Peirce understood the distinction between deduction, induction, and abduction. For him, abduction wasn't anything like IBE. The way I understand Peirce's carving, he thinks deduction is non-ampliative reasoning to a conclusion, induction is ampliative reasoning to a conclusion, and abduction is something like reasoning to a hypothesis space or generating candidate explanations. So we use abduction to generate hypotheses, we use deduction to work out the consequences of hypotheses, and we use induction to confirm and disconfirm hypotheses. Might be that AI is also bad at abduction in Peirce's sense.